As large models become larger, another problem is emerging: the larger the model, the higher the inference cost, but the performance is not necessarily more stable. In particular, when dealing with open and complex tasks, the model lacks clear criteria for judgment, and the feedback mechanism is too simple
Recently, Tsinghua University and DeepSeek jointly proposed one new solution: Self-Principled Critique Tuning (SPCT).
The starting point of this technology is clear – it is not to “stack data” or “stack computing power” again, but to let AI generate judgment standards while generating answers and use these standards to evaluate whether the answers are reasonable.
In other words, allow the model to have the ability to “self-correct” during the inference phase, rather than relying solely on human feedback during the training phase.
1. Model training requires a “judge”
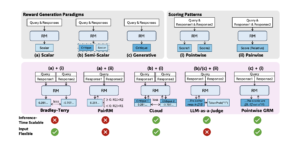 So, the model starts to need the “reward model” (Reward Models, RMs), As the “judge” standing on the side to score.
So, the model starts to need the “reward model” (Reward Models, RMs), As the “judge” standing on the side to score.
But nowadays, referees mostly only rule on a win or lose on a simple question. Once you encounter vague emotions, subjective preferences, and diverse scenarios, you become confused.
2. “Refusal to learn + fine-tuning the rules,” practice boxing and heart
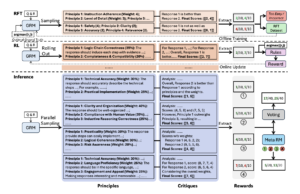
Stage 1: Rejective Fine-Tuning
The model first has to learn how to write a good review. If the output of the critical logic is confused, the conclusion is biased, all refuse to adopt and refuse to learn. Only those cases that are judged to be consistent with “true good answers” are retained to feed the model.
This stage is like a “reviewer” of the model’s training data, taking the best from the worst.
Phase 2: Rule-based Reinforcement Learning (Rule-based RL)
Then there’s the practical application: give the model a question, write its own rating rules, write its reviews, and then rely on simple pre-set rules (like, “Did you pick the right answer?”). ) Here’s a score.
It’s like a reverse Reformation AI: “Principles are not meant to be taken from you; they are meant to judge the world.”
3. A small body has great energy.
The greatest charm of this process is three words – “scalability”.
DeepSeek found in the experiment that even if only a small model such as Gemma-2-27B is used as the basis, the DeepSeek-GRM-27B model generated after fine-tuning by SPCT can actually beat the opponent that is more than ten times larger than it.
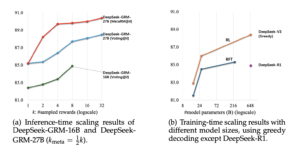
For example:
✨ More than GPT-4o , Nemotron-4-340B-Reward
✨ With 32 samples, the performance is equal to or even better than the 671B level model
✨ The delay is only 1.4 seconds, but training costs less than GPT-4o 99%
✨ More stable and less biased
A 27 billion parameter model, through self-criticism, can go from small to large.
Moreover, it is better in terms of interpretability: not only can you know how many points the model gives, but also why it gives this score .
4. Get out of science and into reality.
This technology is not only academic showmanship; it is also full of imagination for the actual industry:
✅ In the customer service system
✅ In high-risk fields such as finance and medicine, it can generate structured and logically coherent judgment reports and provide a “chain of evidence.”
✅ In creative content generation, it can judge whether the idea is “emotionally right” and “rhythmically natural” and even assist in editing and writing.
More importantly, it greatly lowers the threshold. DeepSeek tests show that SPCT training requires 90% less manual annotation and 73% less energy.
5. Being bigger is no better than being smarter
The SPCT has brought about a paradigm shift.
The SPCT represents a new way of thinking: no longer relying on the heap of resources to overwhelm the opponent, but relying on structural design to understand complexity and adapt to diversity.
In the future, this technology may become the standard technology for large model inference, or it may become a powerful referee to judge whether the content is “qualified” or even become a must-have central node for enterprises to deploy AI.
The DeepSeek team says the technology will be open and open-source.
And for their next-generation R2 model, it is also likely that the official debut will be soon.